As discussed in previous posts, validity refers to the proper inferences for and uses of assessment results. Assessment results are often in the form of assessment scores, and the valid inferences may depend heavily on how we format, label, report, and distribute those scores.
At the core of most assessment results are raw scores. Raw scores are simply the number of points earned by participants based on their responses to items in an assessment. Raw scores are convenient because they are easy to calculate and easy to communicate to participants and stakeholders. However, their interpretation may be constrained.
In their chapter in Educational Measurement (4th ed.), Cohen and Wollack explain that “raw scores have little clear meaning beyond the particular set of questions and the specific test administration.” This is often fine when our inferences are intended to be limited to a specific assessment administration, but what about further inferences?
Peterson, Kolen, and Hoover stated in their chapter in Educational Measurement (3rd ed.) that “the main purpose of scaling is to aid users in interpreting test results.” So when other inferences need to be made about the participants’ results, it is common to transform participants’ scored responses into a more meaningful measure.
When raw scores do not support the desired inference, then we may need to create a scale score. In his chapter in Educational Measurement (4th ed.), Kolen explains that “scaling is the process of associating numbers or other ordered indicators with the performance of examinees.” Scaling examples include percentage scores to be used for topic comparisons within an assessment, equating scores so that scores form multiple forms can be used interchangeably, or scaling IRT theta values so that all reported scores are positive values. SAT scores are examples of the latter two cases. There are many scaling procedures, and a full discussion is not possible here. (If you’d like to know more about this, I’d suggest reading Kolen’s chapter, referenced above).
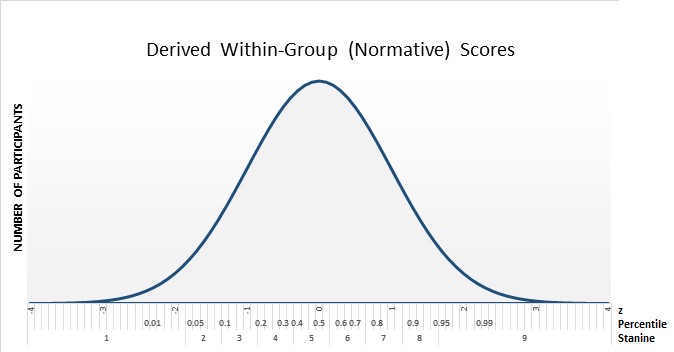
Cohen and Wollack also describe two types of derived scores: developmental scores and within-group scores. These derived scores are designed to support specific types of inferences. Developmental scores show a student’s progress in relation to defined developmental milestones, such as grade equivalency scores used in education assessments. Within-group scores demonstrate a participant’s normative performance relative to a sample of participants. Within-group scores include standardized z scores, percentiles, and stanines.
Sometimes numerical scores cannot support the inference we want, and we give meaning to the assessment scores with a different ordered indicator. A common example is the use of performance level descriptors (PLDs, also known as achievement level descriptors or score band definitions). PLDs describe the average performance, abilities, or knowledge of participants who earn scores within a defined range. PLDs are often very detailed, though shortened versions may be used for reporting. In addition to the PLDs, performance levels (e.g., Pass/Fail, Does Not Meet/Meets/Exceeds) provide labels that tell users how to interpret the scores. In some assessment designs, performance levels and PLDs are reported without any scores. For example, an assessment may continue until a certain error threshold is met to determine which performance level should be assigned to the participant’s performance. If the participant performs very well consistently from the start, the assessment might end early and simply assign a “Pass” performance level rather than making the participant answer more items.